[cue id=”5633″]
Humanoids A to Z: A Modern Glossary for Humanoid Robotics
In 2025, humanoid robots are no longer a long-term bet, they’re entering production. Major industrial players are partnering with robotics companies, moving humanoids out of labs and into real workflows faster than expected. According to a recent Morgan Stanley article, by 2050 the number of humanoid robots could approach 1 billion, with the market projected to surpass $5 trillion.
But progress in this space comes with complexity. Humanoids combine various technologies and mechanisms across its hardware and software, including high-DOF mechanics, real-time whole-body control, reinforcement learning, or foundation-scale perception models among others. Even familiar terms like “fall recovery” or “training data” take on new meaning in humanoid robotics context.
That’s why we created this glossary: a guide to the terminology shaping the field built to help you move fluently through the language of next-gen robotics.
A
Actuators
Actuators turn energy into movement giving humanoid robots the strength, speed, and precision to walk, lift, balance, and recover. Without them, even the smartest robot is just a statue.
Most humanoids rely on electric motors with gear reductions (precise but rigid) or hydraulic systems (powerful but heavy and complex). Some joints also use strain-wave, planetary, or ball screw drives to balance torque density, weight, and backlash — each suited for different loads from hips to wrists. But new trends are shifting the landscape:
- Series Elastic Actuators (SEAs) add compliance and impact absorption, improving safety and resilience.
- Direct-drive motors offer smoother, quieter control without bulky gearboxes.
- Sensorized actuators integrate force and position sensing for real-time feedback.
- Modular designs make repair and iteration easier at scale.
Some of the most radical advances come from emerging research in soft robotics — like fiber-based actuators inspired by rope weaving, which offer programmable elasticity in lightweight, flexible forms.
Application Layer
The application layer defines what a humanoid robot does and how humans interact with it. It sits above control and perception, orchestrating high-level tasks like fetching tools, guiding users, or running mission scripts. This is where voice interfaces, UI frameworks, and task planners live.
Modern systems integrate application logic with foundation models and multimodal input, turning open-ended commands into structured behavior. The goal isn’t just automation, but usability: task abstraction, domain adaptation, and human-friendly interaction.
In commercial deployments, the application layer supports use-case-specific behavior without retraining core models — whether that’s shelf restocking, guided tours, or safety checks. Architecturally, this layer connects cloud services, onboard policies, and operator controls into a unified logic stack.
As humanoids move from labs to logistics and retail, the application layer becomes the differentiator between a general-purpose robot and one that solves a specific problem.
Autonomy
Autonomy is the goal behind humanoid robotics: operating in unstructured, dynamic environments without step-by-step instruction. But it’s not a binary switch, it’s a layered stack of systems, from low-level motion control to high-level task planning and reasoning.
Today’s humanoids combine model-predictive control (for balance and locomotion), behavior trees (for structured actions), and increasingly, transformer-based planners that interpret open-ended commands.
The rise of Vision-Language-Action (VLA) models marks a major shift — integrating visual input, language understanding, and motor output into a unified policy. Recent systems demonstrate long-horizon planning, manipulation, and recovery behavior in previously unseen spaces.
Emerging architectures mix cloud-based reasoning with onboard control, enabling humanoids to respond quickly while drawing on massive world models.
Artificial Intelligence (AI)
Artificial intelligence now drives every layer of humanoid robotics from vision and language to manipulation and planning. Early systems ran on hand-coded rules. Today’s robots learn from multimodal data, simulate before acting, and generalize far beyond their training sets.
The most advanced models unify perception, language, and motor control into end-to-end policies, turning abstract prompts into grounded action. These systems don’t just perform tasks, they infer what the task is, decide how to do it, and adapt when it changes.
The focus is shifting from narrow skillsets to generalization: training models that transfer across tools, environments, and even robot types.

The Open X-Embodiment dataset trains AI across 22 robot types uniting tasks like grasping, folding, and drawer-opening into a single, generalizable control system. Source: Open X-Embodiment: Robotic Learning Datasets and RT-X Models
B
Bipedal
Bipedal locomotion gives humanoid robots access to the world we built: stairs, curbs, doorways, uneven flooring. But walking on two legs is one of the hardest problems in robotics.
Staying upright demands real-time coordination of balance, force, and motion across dozens of joints. Most systems start with model-based control — like Zero Moment Point (ZMP) or Capture Point strategies — to prevent tipping. But natural motion requires anticipatory dynamics, whole-body coordination, and responses that can adapt to changing terrain or sudden disturbances.
Unlike wheeled robots, bipedal systems must continually fall and catch themselves. Walking, as it turns out, is just controlled instability.
Balance Control
Balance control is what keeps humanoid robots upright when the world pushes back. It’s how they respond to slips, bumps, uneven terrain, or shifting loads — by recalculating movement in real time, across the whole body.
Bipedal locomotion is hard, and balance explains why. Traditional methods use feedback loops based on Zero Moment Point or center-of-mass tracking. But modern systems are moving toward learned, general-purpose policies that adapt to uncertainty, noise, and delay.

Battery
Battery design defines how long a humanoid robot can remain useful, mobile, and safe. Runtime depends not only on battery capacity, but also on how the robot moves, senses, and computes. Every additional joint, sensor, or onboard model increases power demand. Managing that demand is critical for deploying robots outside controlled environments.
Efficiency depends on tight coordination between hardware and software. Locomotion speed, joint torque, thermal load, and neural inference all contribute to energy consumption. Strategies such as model quantization, batch size tuning, and adaptive power modes help reduce drain without sacrificing real-time performance.
One recent study of LLM inference on edge accelerators shows how energy draw varies with model configuration and runtime choices — highlighting trade-offs that shape battery-constrained deployment.
Battery life is no longer a passive specification, it is a dynamic engineering target shaped by the robot’s entire computational and mechanical behavior.
Behavior Learning
Behavior learning lets humanoid robots map goals to actions without explicit scripts or step-by-step instructions. It’s about how they move, as well as how they decide what to do in dynamic, uncertain environments.
Instead of hardcoding sequences (“open drawer, grasp tool”), robots learn behaviors through imitation, reinforcement, and trial-based adaptation. This enables them to discover action strategies that respond to context: what’s in front of them, what’s changed, and what might happen next.
Modern approaches integrate perception and policy learning into feedback-rich loops, letting behaviors emerge from success criteria rather than direct supervision.
BOM Costs
The bill of materials (BOM) cost is a core constraint on scalable humanoid deployment. According to Interact Analysis (Humanoid Robots – 2025), joint actuators typically account for over 30 percent of the total BOM in high-configuration humanoids, and more than 50 percent in simpler models without dexterous hands or advanced sensors.
Each full-sized robot may include dozens of actuators, with different torque, control, and mechanical demands depending on joint position. This makes actuator design and supply capacity central to cost structure and scale-up feasibility.
Vendors are developing integrated joint modules that combine motors, gearboxes, encoders, and drives. These reduce system weight and volume but raise initial development costs in the absence of standardization.
As more suppliers introduce off-the-shelf actuator products, BOM optimization is becoming a competitive differentiator between lab-bound prototypes and commercially viable platforms.
C
Control Systems
Control systems translate decisions into motion. Sitting between high-level planners (“go pick that up”) and low-level actuators (motors and joints), they ensure that every movement is stable, safe, and physically achievable.
Classic robots followed predefined motion trajectories using PID loops. But humanoids operate in messier conditions: slippery floors, variable contact, shifting payloads. Today’s systems blend model-predictive control (MPC) with learned policies, allowing them to adapt in real time.
Researchers are exploring neural feedback controllers trained in simulation and fine-tuned on hardware aiming for resilience, precision, and rapid recovery from disturbance. The frontier lies in closed-loop stacks, where perception, planning, and execution constantly inform one another. This integration is essential for humanoids to move fluidly and safely in complex environments.
Commercialization of Humanoid Robots
Humanoid robots are entering pilot deployments across logistics, retail, and manufacturing. The pitch: general-purpose, bipedal machines that can work in human spaces without expensive retooling.
This shift is driven by technical progress — faster control loops, better perception, and scalable foundation models — but also by timing. Persistent labor shortages and supply chain volatility have created new demand for flexible automation. Major tech players and startups alike are securing supply chain deals and pilot partnerships to bring lab-scale robots to commercial floors.
Venture capital is pouring in. Governments are backing national robotics programs. Research talent is moving fast from academia to startups.
Goldman Sachs Research projects that the global market for humanoid robots could reach $38 billion by 2035, with shipments rising to 1.4 million units. This revision reflects faster-than-expected cost declines, advances in AI, and an accelerated timeline for deployment in both industrial and consumer settings.
For Humanoid, commercialization is a top priority. The company is developing HMND 01 robots with a clear focus on practical, market-ready solutions rather than just robotics research. The first use cases include simple pick-and-place tasks, like taking items from shelves and putting them into totes. The company was founded in May 2024 and is already moving into commercial testing with leading retailers just a year later.
Controllers
Controllers are the software layer that translates decisions into motion. They take high-level commands and compute the precise torques, forces, or trajectories needed for actuators to execute safely and accurately.
In humanoid robotics, this means tuning control for rotary actuators with strain-wave or planetary gearboxes, managing backlash, compliance, and torque ripple while coordinating dozens of joints at the same time.
Traditional PID loops (Proportional-Integral-Derivative) are still used for low-level control, but modern systems often rely on model-predictive control (MPC), whole-body controllers, or hybrid architectures that combine physics models with learned behaviors.
Cross-embodiment
Cross-embodiment refers to training or adapting robotic policies across different physical platforms. Instead of developing a control model for a single robot, engineers aim to generalize behaviors across bodies with varying limb lengths, joint types, or actuation systems. The goal is to reduce per-robot training cost and improve skill transfer.
Recent models like RT-X and Open X-Embodiment use multi-robot datasets to align control across morphologies. Policies are conditioned on embodiment-specific inputs while sharing structure across tasks. In simulation, this enables curriculum learning and zero-shot transfer. In real-world use, it supports faster deployment across fleets or hardware revisions.
Cross-embodiment is now central to scaling humanoid intelligence: when one robot learns, the whole system improves.
Cybernetic learning
Cybernetic learning refers to feedback-driven adaptation, where a robot uses continuous sensing to compare outcomes with goals and adjust behavior in real time. Unlike static policies or offline training, it embeds control within a loop that monitors performance and corrects errors as they emerge.
In humanoid systems, cybernetic learning connects low-level reflexes with high-level objectives. It enables balance, compliance, or energy optimization by aligning perception, control, and actuation in a closed loop. This approach is used in fall recovery, adaptive locomotion, and joint-level correction, where decisions must respond to shifting terrain, payloads, or intent.
Cybernetic learning draws from classical control theory but extends it through modern policy updates, real-time inference, and onboard feedback. It turns learning into a regulatory function, giving robots the capacity to self-correct.
D
Data
In humanoid robotics, data is what connects physical experience to model updates. Logs, trajectories, video, force feedback, and joint states drive the training of perception, control, and policy systems. But most robot data is narrow: it reflects structured environments, repeated tasks, or specific embodiments.
Data scarcity limits generalization, while lack of diversity can make models brittle. One-off demonstrations or simulation-only logs rarely transfer well. This has led to large-scale efforts to collect more varied, real-world data across robots, settings, and failure cases.
‘Data as is’ becomes the training truth. If what’s collected is biased or low quality, learning stalls. The next breakthroughs in humanoid intelligence may depend more on what data is used than how the model is designed.
Data Flywheel
The data flywheel is a self-reinforcing loop: robots act, generate data, learn from it, and act better. In humanoid robotics, this feedback cycle is core to improving perception, control, and decision-making over time. Each deployment, simulation, or failure creates logs, videos, and trajectories that feed the next round of training.
The flywheel effect accelerates with scale. Offline reinforcement learning, imitation learning, and foundation model fine-tuning all benefit from more and more diverse data. Many teams now operate dedicated ‘data factories’ — fleets of robots logging millions of real-world hours to feed the flywheel.
The challenge is filtering for value: not all data teaches. The future of humanoids depends on how fast, and how well, they can learn from their own experience.

Data Flywheel at Humanoid
Deployment
Deployment is when humanoid robots leave the lab and enter the real world. It’s where theory meets the factory floor, warehouse uncertainty, and retail unpredictability. A deployed robot must manage long shifts, ambiguous inputs, and tasks that don’t match clean scripts. It needs fallback strategies, safety overrides, and remote monitoring.
Deployment pressure exposes edge cases that academic testing can’t. But it also triggers iteration: field logs become training data, and failures become new features. Integration is often the bottleneck — robots must slot into workflows, infrastructure, and operator habits that weren’t built for them. For many teams, this takes months. Humanoid was founded on a different assumption: that integration should take weeks, not quarters.
Dexterity
Dexterity lets humanoids interact meaningfully with the physical world: grasping tools, threading cables, handing over delicate objects. It allows them not just to pick things up, but to use their hands purposefully.
Language models can parse commands like “bring me the yellow bowl,” but physical manipulation demands fast, low-level control. Systems must account for friction, slippage, compliance, and contact uncertainty in real time.
Today’s best approaches combine trajectory optimization, tactile sensing, force feedback, and learned reflexes to perform in contact-rich, unstructured environments. The trend is shifting away from rigid scripts and brute-force actuation toward adaptive controllers that respond fluidly to what the robot feels, not just what it was told.
Degrees of Freedom
Degrees of Freedom (DoF) define how many independent ways a robot can move. A rigid body in 3D space has six: three for position (X, Y, Z) and three for rotation (roll, pitch, yaw). Humanoid robots often include 30 to 40 or even more DoF, with multi-jointed limbs, articulated torsos, and expressive heads.
For comparison, the human body has over 200 skeletal DoF, though only about 80 are typically used in whole-body motion. The human hand alone contributes over 20.
This flexibility enables fluid motion, fine manipulation, and better balance, but also makes control harder. Each DoF adds complexity, requiring fast coordination across actuators and real-time feedback.
E
End Effectors
End effectors are the tools at the far end of a robot’s limb: the parts that make contact, perform work, and close the loop between intent and action. In humanoids, they’re often grippers or hands, but can also include screwdrivers, sensors, suction pads, or specialized instruments.
They define what a robot can actually do. Swapping a gripper for a welding torch, or a camera for a paintbrush, instantly transforms capabilities. In modular systems, end effectors can be interchanged mid-task or customized per workflow.
Design matters: the weight, torque limits, sensing, and compliance of an end effector all shape how well a robot handles real-world tasks.
End-to-End
End-to-end systems learn or operate across the full robotics stack — from raw input to physical action — without hand-tuned intermediate stages. Instead of separate modules for perception, planning, and control, these systems train a unified policy or model that maps sensor data directly to motor commands or task execution.
In humanoid robotics, end-to-end learning simplifies integration and enables adaptability. A robot might learn to walk, grasp, or follow spoken instructions without explicit programming for each subtask. But it comes with trade-offs, including reduced interpretability, higher data demands, and safety concerns during training or deployment.
Ethics
Ethical concerns in humanoid robotics span design, training, deployment, and perception. Human-like form and voice can create false impressions of agency or emotion, leading users to over-trust systems that are task-bound and non-sentient.
Humanoids are marketed for roles across various industries, including logistics, retail, and caregiving — raising concerns about safety, human-robot interaction, data privacy, or growing dependence on automation.
As humanoids move into public space, their presence carries social and moral weight. The way a robot moves, speaks, and appears will shape how people respond — and who bears responsibility when they do. That’s why humanoid robotics companies should adopt ethical standards from the very beginning.
Edge Computing
Edge computing means processing data locally (on the robot) rather than in the cloud. For humanoids, this isn’t just about speed, but also about safety.
Walking, grasping, and reacting all require low-latency control loops. Cloud AI can help with planning and language, but real-time functions like sensor fusion, motor control, and fall recovery must run onboard.
While many systems still offload high-level tasks, new research shows transformer-based inference, gaze control, and state estimation running directly at the edge, some at 30Hz or more. Many systems now split workloads across onboard and cloud computing to balance latency and power draw. As model compression and chip design evolve, foundation-model behavior is inching closer to real-time embodiment.
F
Firmware
Firmware is the embedded control layer that links hardware to action. It handles startup, real-time motor control, sensor polling, and safety logic, often with no room for failure.
Glitches at this level can trigger actuator faults, sensor noise, or system-wide crashes. But when engineered well, firmware enables fast reflexes, reliable fall recovery, and real-time safety responses that operate independently of cloud or OS layers.
Modern humanoids rely on modular firmware stacks running on real-time operating systems (RTOS), balancing timing precision with fault tolerance. The next wave of development includes adaptive firmware, runtime configurability, and certifiable safety layers — all designed to bring high-speed control in sync with dynamic environments.
Fallback Strategy
Fallback strategy refers to a safety and continuity mechanism in deployed robots. When a robot fails to complete a task — due to uncertainty, sensor noise, or unexpected conditions — a remote teleoperator can intervene instantly to guide or override its behavior. The handoff is seamless: the user or client experiences no disruption, even though control temporarily shifts away from full autonomy.
This approach ensures workflows continue without pause, even when the robot encounters a failure case. It relies on a model known as shared autonomy, where the robot operates autonomously but remains connected to human support that can step in when needed without direct physical involvement on-site.
In humanoid deployments, fallback strategies are essential for maintaining reliability in early-stage logistics, retail, or inspection use.
Fall Recovery
For humanoids, falling is inevitable. Whether caused by a collision, terrain shift, or control error, what matters is recovery — fast, safe, and autonomous. A robot that can’t stand up again isn’t field-ready. It’s a liability.
Effective recovery combines compliant joints, impact resilience, body awareness, and motion planning. The robot must absorb the fall, assess its orientation, and reorient to a stable stance without assistance.
Many systems now learn this in simulation, practicing thousands of falls to refine how to roll, brace, and regain footing. These strategies are increasingly transferred to hardware, enabling robots to recover quickly and safely in the real world.
Fleet Management
Fleet management refers to the systems used to coordinate multiple deployed robots: tracking their status, assigning tasks, updating software, and handling exceptions in real time. In humanoid robotics, it’s a control layer that turns individual units into an operational network.
Unlike static automation, humanoids often share spaces with humans and require constant adaptation. Fleet software monitors uptime, fallbacks, battery levels, and task queues across robots in warehouses, retail sites, or service environments. It enables centralized scheduling, load balancing, and remote intervention when a robot encounters an edge case.
Effective fleet management is essential for scaling humanoids from pilot to production. Without it, scaling robots leads to coordination bottlenecks and failure points.
Foundation Models
Foundation models in robotics are large, general-purpose models trained on broad datasets spanning multiple robots, tasks, and modalities. When applied to humanoids, they often operate end-to-end: mapping raw inputs like vision, proprioception, or language directly to control actions, without task-specific modules or manually engineered pipelines.
This architecture enables flexible behavior across diverse environments, with a single model adapting to perception, planning, and actuation. NVIDIA’s GR00T N1, introduced in 2025, and Google DeepMind’s RT‑2, released in 2023, are examples of vision-language-action foundation models trained end-to-end. These systems map sensory inputs to robot actions, enabling generalist performance across tasks and platforms, with GR00T N1 pushing this approach toward humanoid-scale deployment.
In humanoids, foundation models are now a core strategy for scaling capability — compressing what once required dozens of hand-built modules into a single adaptive model that learns from interaction.
Full-Body Motion
To operate in human environments, humanoid robots must move as unified bodies, not just isolated limbs. Whether reaching while walking, catching a stumble, or using multiple contacts, full-body motion demands synchronized control across legs, arms, torso, and even gaze.
This coordination requires frameworks that account for kinematics, dynamics, and real-time feedback. Leading approaches combine momentum-based planning, contact-aware optimization, and neural warm-starts to speed up response without sacrificing stability.

A real-time controller from Seoul National University uses predictive models and learned warm-starts to plan coordinated whole-body motion — balancing speed and stability in dynamic tasks. Source: Real-time Whole-body Model Predictive Control for Bipedal Locomotion with a Novel Kino-dynamic Model and Warm-start Method
G
Generative AI
In humanoid robotics, generative AI is becoming the link between perception and action. These models don’t just label data but produce it — trajectories, grasp plans, motion sequences, and even control policies — from images, language, or sensor input.
A 2024 survey on robotic manipulation outlined a three-layer framework: foundation models provide broad pretraining; intermediate models translate across modalities (like vision to code); and policy generators output actionable control sequences.

Generative models now power every stage of robot learning — producing synthetic training data, generating perception-to-action mappings, and creating control policies that can be executed on hardware. Source: Generative Artificial Intelligence in Robotic Manipulation: A Survey
Recent systems use vision-language models to produce zero-shot behaviors, placing unseen objects, adapting to novel instructions, and writing control logic on the fly. The frontier is embodied improvisation: agents that don’t just execute plans, but generate them in real time.
General-Purpose
Most robots today specialize in several tasks. General-purpose humanoids aim to change that by adapting to a wide range of tasks, tools, and environments on a single platform.
What makes a robot general-purpose is the ability to abstract and reuse skills combining multimodal perception, transferable control policies, and high-level reasoning to turn open-ended prompts into coordinated actions.
Modern systems increasingly blend reusable control layers with foundation-model reasoning. This allows them to perform multi-step tasks in homes, warehouses, and clinics without task-specific reprogramming.
GPU
A GPU (graphics processing unit) is a parallel computing processor originally designed for rendering images, now central to AI workloads. In humanoid robots, GPUs accelerate tasks like vision processing, object recognition, and policy inference from foundation models.
Modern edge GPUs, such as the NVIDIA Jetson series, allow real-time execution of large neural networks on board the robot. This enables fast perception and decision-making without relying on cloud latency. GPU selection affects runtime, energy draw, and the feasibility of end-to-end learning architectures.
As models grow larger and more capable, GPU capacity is becoming a bottleneck shaping which models can run in real-world deployments and how long a robot can operate per charge.
Grippers
Grippers are the hands of humanoid robots — the final contact point between robot and world. They enable picking, placing, holding, turning, and everything in between. Most fall into two camps: rigid, multi-fingered designs for precision, or adaptive, underactuated models that conform to shape with fewer actuators.
Modern grippers integrate tactile sensors, force feedback, and soft materials to improve robustness and versatility. In industrial use, they must handle fragile items and heavy tools with equal reliability, often in unpredictable poses or variable environments. These tactile sensors don’t just improve grip, they generate force and contact data that feeds better training loops.
H
Hardware
The body of a humanoid robot is a balance of weight, torque, and responsiveness. Hardware shapes everything a robot can do, from whole-body control to safe human interaction.
Modern systems use lightweight frames, high-torque actuators, and modular joints with embedded force sensors. Advances in motor control now allow millisecond-level torque adjustments, enabling smoother, more adaptive movement.
Every hardware decision carries a tradeoff: speed versus force, compliance versus rigidity, battery life versus performance. No matter how advanced the software, every action still depends on physical systems delivering the right force at the right time.
Humanoid Robot
Humanoid robots are designed with humanlike proportions: two arms, two legs (or wheels), a torso, and often a head. This isn’t mimicry for its own sake, it’s a compatibility layer. Our world — from door handles to toolboxes — is built for human bodies. The humanoid form gives robots the best chance of functioning in it without redesigning everything around them.
Unlike industrial arms or quadruped robots, humanoids aim to be generalists. They walk, climb, reach, carry, and interact in human environments. But the form factor adds complexity: balancing on two legs, coordinating multi-joint motion, and recovering from falls are all harder than rolling on wheels or repeating a fixed trajectory.
Form is just the beginning. What defines a humanoid robot is its ability to integrate sensing, planning, and control across the whole body — enabling it not just to mimic human motion, but to work and adapt like a teammate.
Human-Robot Interaction
Human-robot interaction (HRI) refers to the ways robots and humans communicate, coordinate, and share space. In humanoid robotics, HRI spans physical collaboration, voice and gesture interfaces, safety protocols, and shared autonomy. Robots working in warehouses, retail, service sectors, or households must adapt to human behavior in real time: not just executing commands, but responding to intent.
Modern systems combine voice recognition, gaze tracking, gesture sensing, and proximity detection to read subtle cues. Predictive models anticipate human actions to enable smoother coordination. Shared autonomy allows robots to manage low-level tasks while humans guide high-level goals.
In some systems, it also underpins fallback strategies, where remote operators intervene seamlessly during failure cases. The challenge is making interaction natural, safe, and productive without retraining people to fit the machine.
I
Imitation Learning
Imitation learning trains robots to perform tasks by observing human behavior, without writing explicit instructions. A person demonstrates a task, and the robot learns to replicate it. Early systems relied on motion capture or physical guidance. Newer models learn directly from video, speech, or sensor streams.
Recent work like Value-Implicit Pretraining (VIP) uses human videos to train goal-aware visual representations. These can guide robotic behavior without labeled actions or expert demonstrations, making imitation learning more scalable and data-efficient.
J
Joints
Joints define how humanoid robots move. They connect limbs, control rotation or translation, and determine each degree of freedom. Managing joints is central to balance, dexterity, and coordinated whole-body motion.
Designs include rotary joints, prismatic sliders, and — in experimental systems — soft continuum joints. More joints enable finer control, but increase complexity, weight, and power demands.
Modern humanoids rely on modular, sensorized, and backdrivable joints to support compliant interaction, fall recovery, and safe manipulation. The art of joint design is balancing precision, speed, and force while keeping control achievable.
K
Kinematics
Kinematics describes how a robot’s limbs move in space without accounting for the forces behind them. In humanoid robotics, it’s essential for planning poses, gestures, and walking gaits.
Forward kinematics calculates limb positions from known joint angles. Inverse kinematics (IK) works in reverse, computing joint angles needed to reach a target position. IK is especially critical for manipulation, balance, and coordinated whole-body motion.
Modern systems use hybrid solvers that blend geometric methods with optimization techniques. These handle joint limits, redundancies, and nonlinear behaviors while integrating real-time feedback from vision and touch.
L
Large Language Models (LLMs)
Large Language Models (LLMs) give humanoid robots the ability to understand, generalize, and respond to natural-language instructions. Instead of relying on hand-coded scripts, they generate executable plans and even write control policies on the fly. Paired with perception systems, LLMs help robots clarify intent and complete tasks.
The frontier is grounding — linking language to physical action. Projects like SayCan, RT-2, and PaLM-E laid the groundwork, integrating LLMs with sensor data and planning stacks to turn abstract prompts into embodied behavior.
Recent models have pushed this further: GR00T N1 (NVIDIA) enables end-to-end control on humanoids; Gemini Robotics (DeepMind) supports language-conditioned planning and on-device inference; Pi-Zero (Physical Intelligence) uses continuous control at 50 Hz across embodiments.
These systems define the emerging class of vision-language-action models that bring LLMs into physical space — turning generalist reasoning into real-world performance.
Locomotion Control
Locomotion control enables humanoid robots to walk, balance, and adjust in real time — across flat surfaces, stairs, or uneven terrain. It combines trajectory planning, inverse kinematics, and feedback control to generate stable, coordinated movement.
A key technique is Model Predictive Control (MPC), which simulates future states to plan center-of-mass shifts, adapt footsteps, and recover from slips. MPC allows robots to anticipate rather than react, adjusting gait dynamically as the environment changes.

Different MPC models — simplified, nonlinear, and full-body — offer tradeoffs between computational cost and control fidelity. Source: Humanoid Locomotion and Manipulation: Current Progress and Challenges in Control, Planning, and Learning
Locomotion isn’t a set of preprogrammed moves. It’s a continuous, predictive process where planning, sensing, and control operate in tight synchrony.
M
Manipulation
Manipulation refers to a robot’s ability to influence the world through intentional motion. In humanoid robotics, this includes object handling — grasping, lifting, pushing, and placing — as well as higher-order actions like stacking, tool use, or task sequencing. It requires tight integration between vision, control, contact dynamics, and increasingly, language.
Modern systems use end-to-end visuomotor policies that generalize across tasks. Transformer-based models like RT-X support shared control across robot types and scenarios, while RT-Trajectory adds temporal structure for more fluid motion. Recent research explores novel representations: for instance, FreqPolicy models motion in the frequency domain to enable high-fidelity control from compact latent codes.

Structure in motion: FreqPolicy uses frequency-based trajectory modeling to synthesize smooth, task-aware manipulation from learned codes. Source: FreqPolicy: Frequency Autoregressive Visuomotor Policy with Continuous Tokens
The frontier of manipulation is predictive, multitask, and context-aware: robots that don’t just move things, but anticipate, adapt, and execute with purpose.
Modularity
In humanoid robotics, modularity means building systems from swappable components: arms, sensors, actuators, and even control stacks. This speeds up iteration, simplifies maintenance, and makes it easier to scale designs across platforms.
Modular hardware allows teams to test new gaits, hand designs, or actuator types without rebuilding the entire robot. On the software side, graph-based planners, microservices, and ROS 2 nodes enable targeted upgrades and more robust debugging.
Whether in hardware or software, modularity helps robots evolve faster. For Humanoid, modularity is a key design principle: HMND 01 robots are designed with a modular hardware and software architecture. HMND 01 robots feature modular lower bodies and end-effectors, allowing teams to adapt locomotion and manipulation to different tasks and reduce cost across deployments.
Motion
In humanoid robotics, motion is the visible result of perception, planning, and physics-aware actuation working in sync. Smooth, adaptive movement communicates capability. Awkward motion breaks trust and limits usability.
Early systems used hand-tuned scripts for gestures, gait cycles, and reaching. Today, motion is often learned. Deep models synthesize trajectories from motion capture, video, or simulation. Controllers blend planned motion with corrections from real-time sensory feedback.
Advanced techniques like motion retargeting and skill composition allow robots to adapt human demonstrations and combine actions fluidly. Multi-contact planning and whole-body predictive control now support dynamic, task-aware movement across varied environments.
Motors
Motors are the driving element within the actuators that power every joint in a humanoid robot. They determine torque, precision, efficiency, and responsiveness — key factors in how the actuator performs. The choice of motor — whether brushless DC (BLDC), stepper, or torque-controlled — directly affects agility, payload, and battery life.
Recent designs focus on higher torque density, better thermal management, and tighter integration. Quasi-direct-drive architectures reduce gear complexity while enabling fine force control.
Axial-flux motors with foil windings improve torque output in compact volumes, with commercial examples achieving torque densities of 20–28 Nm/kg. Integrated motor drives (IMDs) combine power electronics and advanced cooling, pushing torque density to 4–10 Nm/kg in recent quasi-direct-drive actuator designs.
High-torque modular design: The Mithra humanoid uses quasi-direct-drive ankle actuators with BLDC motors and torque sensing to support compact, agile 2-DoF control for dynamic walking. Source: Design of Actuators for a Humanoid Robot with Anthropomorphic Characteristics and Running Capability
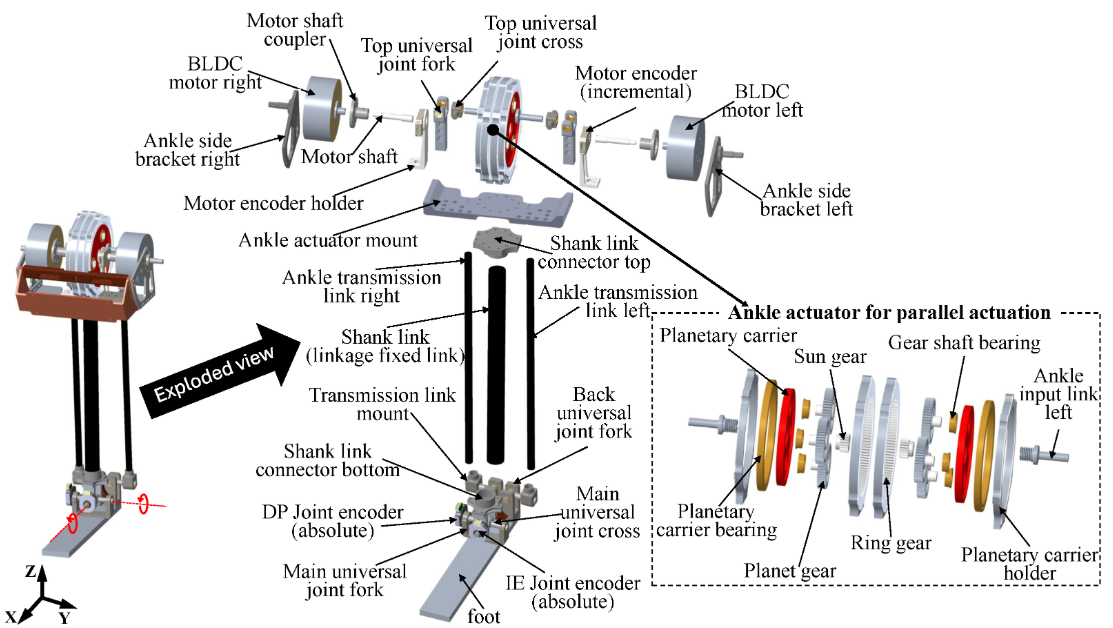
High-frequency winding methods are also improving the speed–torque tradeoff critical for real-time physical interaction.
N
Navigation
For humanoids, navigation is more than path planning. It requires continuous awareness of obstacles, terrain, and intent. Unlike wheeled robots, bipeds must adjust foot placement and balance in real time while moving through unpredictable environments.
Modern systems combine Simultaneous Localization and Mapping (SLAM) — which builds a map while tracking the robot’s position — with terrain-aware planning and depth sensing. Some robots now build semantic maps on the fly, recognizing objects like chairs, doors, or charging stations using vision-language models.
Emerging methods fuse transformer-based perception with motion planning, allowing robots to interpret open-ended commands like “go stand by the door” and respond with grounded, adaptive behavior.
Natural Language Processing
NLP allows humanoid robots to understand and respond to spoken or written instructions. Early systems relied on keyword spotting or intent matching. Today’s models — often based on fine-tuned language transformers — can interpret high-level prompts like “clean up the mess” or “find the red cup,” and translate them into executable actions.
The frontier is semantic grounding. Robots now combine language models with vision and spatial memory to connect words with physical objects, places, and goals. This enables zero-shot reasoning, where new commands are understood without explicit pretraining.
One approach fuses language, visual input, and robot state into a unified model, allowing robots to interpret complex instructions and execute multi-step tasks with context awareness.

Multimodal models combine speech, visual data, and proprioception to plan and execute grounded actions. Source: PaLM-E: An Embodied Multimodal Language Model
The next challenge is making NLP fast, safe, and robust enough for dynamic physical environments.
Neural Networks
Neural networks are the core computational structures that enable humanoid robots to see, move, understand, and adapt. Inspired by biological neurons, they learn patterns and behaviors from data — whether through pretraining or real-world interaction.
In humanoids, convolutional networks process vision; transformer and recurrent architectures handle joint feedback, audio, and time-dependent signals. Some networks translate tactile input into force estimates or generate motion plans from language prompts.
A major trend is multimodal fusion: training networks that integrate visual, inertial, and proprioceptive data to produce coordinated actions. These models increasingly span perception, reasoning, and control in a single architecture.
Neural policies now run on edge devices thanks to pruning, quantization, and specialized hardware. This enables humanoids to adapt in real time without relying solely on cloud-based inference.
O
Open-Source Frameworks
Humanoid robotics thrives on modular, open infrastructure. Rather than reinventing the stack, teams plug into shared frameworks that accelerate development, enforce standards, and ensure interoperability.
ROS 2 underpins many modern systems with real-time-safe messaging, distributed control, and extensible hardware interfaces. Tools like MoveIt enable motion planning, Isaac ROS brings GPU-accelerated perception, and Drake offers rich physical modeling — though often outside the ROS ecosystem.
Simulation platforms such as MuJoCo, PyBullet, and Habitat Lab provide essential training grounds for learning-based control, reinforcement learning, and sim-to-real transfer.
These frameworks also define standards. As foundation models enter robotics, reproducibility, multi-robot scaling, and benchmarking demand shared infrastructure. Initiatives like Open X-Embodiment and RT-X depend on this ecosystem to move fast and stay aligned.
P
Perception
Perception includes object recognition, motion estimation, pose detection, and reading human cues. For embodied robots, it depends on fusing RGB, depth, LiDAR, proprioception, and audio into a coherent model of the environment.
Recent advances combine classical vision pipelines with transformer-based models. Tools like Segment Anything and DINOv2 enable zero-shot segmentation, while diffusion-based methods reconstruct 3D scenes from a single image. Systems like PerAct map visual input directly to manipulation commands.
The frontier now links perception to control. Rather than analyzing scenes in isolation, robots learn visual representations optimized for decision-making. Seeing is no longer the goal, it’s the starting point for intelligent action.
Predictive Models
Predictive models give humanoids foresight. Rather than reacting frame by frame, they estimate how bodies, objects, and environments will evolve. It’s critical for balance, manipulation, and real-time planning. From milliseconds of fall recovery to minutes of task sequencing, prediction shapes control at every scale.
A key trend is internal world models that simulate future outcomes without constant real-world resets. Transformers, diffusion policies, and hybrid physics-learning frameworks are pushing robotic foresight beyond reactive behavior.

One example models how robotic legs interact with granular terrain. Using dimensionality reduction and particle filtering, it predicts dynamic forces more accurately than traditional simulators. Source: Data-Driven Prediction of Dynamic Interactions Between Robot Appendage and Granular Material
Predictive models are becoming part of the control loop — running onboard, learning online, and enabling humanoids to act before the environment changes.
Proof of Concept (POC)
In humanoid robotics, a Proof of Concept (POC) is an early-stage trial that tests whether a robot can successfully perform specific tasks within a defined use case. It is conducted before full-scale deployment and helps evaluate feasibility, performance, and potential value.
A POC typically runs over a limited period and focuses on a clearly defined set of tasks. It may involve basic integration with existing systems, but does not aim to cover the full operational complexity of a long-term deployment.
These early tests are especially important for complex, evolving technologies like humanoid robots. They allow teams to gather real-world feedback, identify areas for improvement, and iterate quickly. While the product used in a POC may differ from the final version, the insights gained are crucial for refining both hardware and software.
POCs also support customer development and market validation: by running early POCs, companies can better understand the real-world needs of their customers, adapt their solutions, and build trust-based relationships that can grow into long-term collaborations. At Humanoid, we see early POCs as a core part of our strategy.
Q
Quality Standards / Requirements
As humanoid robots move from labs to real-world settings the bar is no longer just motion or runtime. It’s safety, reproducibility, resilience, and accountability.
Emerging frameworks like ISO 13482 (for personal care robots) and IEEE P7001 (for ethical design) define how humanoids must behave around people: how they fail, recover, explain decisions, and avoid harm. These standards guide both hardware engineering and system behavior.
Some robotics teams now run structured validation pipelines — drawing from logs, simulation, and real-world feedback to test durability, usability, and long-term reliability.
Without standardized proof, trust is impossible. And without trust, humanoids won’t scale.
R
Reasoning
Reasoning refers to a robot’s ability to infer, plan, and adapt across tasks and environments. In humanoid robotics, reasoning supports high-level decision-making in complex, human-designed spaces — deciding not just how to move, but why, when, and in what sequence. Unlike low-level control, it operates across goals, dependencies, object relationships, and context.
Modern systems incorporate reasoning through Large Language Models, multimodal transformers, and task planners. These models interpret user intent, break down abstract instructions, and sequence actions across manipulation, navigation, or dialogue.
Approaches such as SayCan, MALMM, and A3VLM bring reasoning into robot control by using multimodal input to plan feasible actions. SayCan links LLM-generated plans to real-world affordance scores, MALMM re-plans after failures, and A3VLM infers part interactions to guide articulated manipulation.
For humanoids operating in unstructured spaces, reasoning is a prerequisite for generality. It’s how robots go from scripted behavior to goal-directed autonomy.
Reinforcement Learning
Reinforcement learning (RL) enables robots to develop behaviors by interacting with the environment, receiving feedback, and optimizing their actions over time. In humanoids, RL powers skills like balancing, grasping, locomotion, and fall recovery.
Unlike scripted control, RL thrives in environments with uncertainty: walking on ice, lifting unfamiliar objects, or navigating cluttered rooms. Agents learn what works through repetition, gradually improving policies to maximize long-term success.
Recent trends include sim-to-real transfer (training in simulation, then deploying in hardware), offline RL (learning from logged data), and hierarchical RL (stacking learned behaviors). These techniques aim to reduce training time and improve real-world generalization.
A robot trained with RL tracks a moving pedestrian more smoothly than those using traditional or imitation-based control. While this example focuses on navigation, similar RL methods underpin locomotion, balance, and object interaction in humanoid systems. Source: Human-Robot Navigation using Event-based Cameras and Reinforcement Learning
To scale, RL is increasingly blended with imitation learning, prior knowledge, and foundation models.
Robustness
Robustness is a robot’s ability to function reliably in the real world despite the uneven ground, sensor noise, hardware fatigue, power loss, and software faults. Recent methods include domain randomization, adaptive control loops, and redundant sensing to handle failures before they cascade. Robots now train in simulations full of noise and disruption to prepare for reality.
Compliant joints and soft actuators absorb shock. Hybrid control stacks fuse physics models with learned policies for real-time adjustment under stress. Robots won’t succeed just by performing complex tasks, they must endure unpredictable ones. Robustness turns skills into reliability.
Runtime
Battery runtime refers to how long a humanoid robot can operate on a single charge in real-world conditions. It is shaped by the power demands of actuators, compute hardware, sensors, and the frequency of control and perception loops. Energy use increases sharply during active tasks like locomotion or object manipulation, especially when high-rate inference or whole-body control is involved.
Improving battery runtime requires coordinated hardware and software strategies — from motor efficiency and hardware acceleration to dynamic power scaling and optimized scheduling. Some systems modulate compute load based on task demands, switching between high-performance and low-power modes to conserve energy.
Battery runtime concerns the duration of operation before recharge, not the timing precision of control processes. It complements broader power management efforts that balance energy availability with task complexity and responsiveness.
S
Safety
In humanoid robotics, safety spans both physical interaction and system reliability. Robots must avoid hitting people, dropping objects, or damaging themselves. A safe system walks, grasps, and reasons without cascading failures from misinterpretation or delay.
Hardware plays the first role: compliant actuators, soft shells, and force-limited joints reduce physical risk. Control systems add fall prediction, real-time collision detection, and trajectory constraint solvers. Sensors track force, proximity, and intent to dynamically modulate behavior.
Some platforms ship with embedded emergency stop (“e-stop”) logic — intervening when force, speed, or contact thresholds are breached. Others explore proactive intent recognition, anticipating when a human may cross a path or reach in.
As autonomy grows, safety becomes a question of cognition. Systems must fail safely, be interruptible, and offer behavior that can be verified.
Simulation
Simulation enables humanoid robots to be developed, tested, and trained before they interact with the physical world. It accelerates iteration, reduces hardware risk, and enables safe prototyping of control policies, mechanical systems, and behavior logic.
Modern platforms like Isaac Sim, MuJoCo, and Brax support high-fidelity physics, multi-agent scenes, and contact-rich environments. The central goal is sim-to-real transfer: policies trained virtually that adapt to the unpredictability of the real world.
For example, Humanoid is leveraging NVIDIA technology to address key challenges in robotics development. Using NVIDIA Isaac Sim and NVIDIA Omniverse platforms, Humanoid rapidly iterates their robot in simulation environments, aiming to reduce prototyping cycles to 6 weeks.

Sensors
Sensors convert physical interaction into usable data: light into pixels, force into pressure maps, motion into pose estimates. Cameras, inertial units, tactile arrays, and torque sensors form the foundation of humanoid perception and control.
Modern systems process these inputs simultaneously. Depth cameras reconstruct 3D structure. LiDAR maps surroundings. Tactile sensors detect slip and contact. IMUs (inertial measurement units) track body position and acceleration, enabling real-time balance and fall detection. =

Robotic senses. Source: Robotics: Five Senses plus One—An Overview
The shift is toward multimodal fusion — vision, touch, motion, and audio working together to build a coherent model of the world. High-speed sensing enables reflexes: grip correction, obstacle avoidance, terrain adaptation.
Skill
In humanoid robotics, a skill is a modular behavior that achieves a specific goal when triggered by high-level plans or commands. Unlike monolithic control policies, skills are discrete, reusable units such as grasp object, walk to point, or open drawer. Each skill encapsulates perception, planning, and low-level control tuned for that task, often learned through imitation or reinforcement.
Modern architectures like Being-0 use large vision-language models to interpret natural-language instructions and invoke appropriate skills from a pre-defined library. This approach enables fast response, better generalization, and simpler real-world deployment by offloading task logic to modular skill primitives. Skills can be chained or blended at runtime, supporting long-horizon planning and fallback strategies without end-to-end retraining.
Skills are essential in bridging abstract prompts with grounded, embodied action — making complex autonomy interpretable, composable, and more maintainable.
T
Teleoperation
Teleoperation lets humans control robots in real time — using joysticks, VR rigs, or motion capture systems. It remains essential where autonomy struggles: disaster response, surgery, or robot training.
In humanoid robotics, teleoperation enables both direct control and data generation. Humans perform full-body actions while robots mimic them. These demonstrations feed imitation learning and reinforcement pipelines.
Modern systems leverage markerless MoCap, wearable sensors, and low-latency middleware like ROS or Isaac Sim to stream motion, manage feedback, and maintain safety.
TWIST uses motion capture to drive humanoid robots through complex actions like walking, kicking, and manipulation — blending teleoperation with real-world embodiment. Source: TWIST: Teleoperated Whole-Body Imitation System

Total Cost of Ownership (TCO)
TCO measures the full lifecycle cost of a humanoid robot, not just the purchase price. It includes integration, deployment, maintenance, energy consumption, software updates, operator training, and downtime. In robotics, TCO is the clearest metric of economic viability.
Vendors increasingly emphasize low-TCO design: modular hardware, remote diagnostics, and upgradeable software stacks that reduce service costs and extend lifespan. As competition heats up, TCO may determine which platforms scale and which stall at the prototype stage.
Training
Training gives humanoid robots the ability to perceive, plan, and act. It turns recorded data — from sensors, demonstrations, or simulations — into working models that guide real-world behavior.
Training methods vary by architecture. Imitation learning uses expert demonstrations to copy behaviors. Reinforcement learning explores through trial and error, optimizing reward-based performance. End-to-end approaches, especially those using foundation models, consume vast multimodal datasets — video, language, 3D scans — to generalize across tasks.
Modern humanoids blend multiple training sources: real-world logs, simulation rollouts, synthetic scenes, and teleoperated sessions. The goal is data efficiency: learning more from less, with fewer collisions, faster convergence, and better generalization.
Training doesn’t end when a robot ships. Logs from deployment become new supervision. Robots improve not just in labs, but in the field — tightening the feedback loop between experience and intelligence.
U
Use Cases
Humanoid robots are built to operate in environments designed for people. Their form fits our stairs, tools, vehicles, and workspaces, offering utility without redesigning the world.
Current deployments focus on logistics, inspection, and service: restocking shelves, unloading trucks, delivering packages, guiding visitors. Emerging use cases include eldercare, disaster response, and construction — domains where versatility matters more than raw speed. In labs, humanoids function as testbeds for locomotion, manipulation, and embodied AI. The long-goal remains: adaptable, general-purpose robots that work in the same space with humans.
Humanoid is starting with industrial applications, targeting retail and manufacturing facilities, logistics and fulfillment centers, and warehouses. HMND 01 robots will provide highly efficient services such as goods handling, picking and machine feeding operation, kitting and part handling.
Usability
In robotics, usability means how easily a human can operate, configure, and trust a system. For humanoids, it’s not just about capability — but how quickly someone can deploy it, safely and without deep expertise.
Modern systems prioritize intuitive interfaces, rapid setup, and fail-safes that degrade gracefully. A robot that needs a PhD to operate it fails the usability test.
Low-code and natural language interfaces are shifting expectations. Tools like SayCan, VoxPoser, and RobotGPT let users issue high-level commands instead of writing ROS behavior trees, enabling non-experts to control complex systems.

One example of this usability trend is the integration of ChatGPT to turn natural language commands into ROS 2 robot control, simplifying interaction. Source: Reducing Latency in LLM-Based Natural Language Commands Processing for Robot Navigation
V
Vision-Language-Action (VLA) Models
VLA models unify perception, language, and control — enabling robots to interpret visual scenes, parse spoken or written commands, and perform appropriate actions, all in a single computational loop.
Unlike traditional pipelines that link vision, NLP, and policy as separate modules, VLA systems train with shared representations or fully end-to-end architectures. This allows robots to respond to complex prompts like “Pick up the red cup on the left and hand it to me,” with grounded, executable behavior.
Examples include SayCan, VoxPoser, VIMA, and PerAct (when paired with language planners). Many build on foundation models like CLIP, GPT-4, or RT-2 to support generalization across tasks and environments. Some VLA systems now also fuse tactile data for richer physical grounding and manipulation.
Voice Interaction
Voice interfaces turn spoken language into robotic behavior. For humanoids, this enables hands-free control, natural delegation, and access for non-technical users.
Today’s pipelines use automatic speech recognition (ASR) paired with large language models to process open-ended instructions and generate grounded, executable actions.

An example of this approach, OpenVLA turns natural language—including voice commands—into real-world robot behavior, integrating perception, intent parsing, and task planning. Source: OpenVLA: An Open-Source Vision-Language-Action Model
The challenge now is grounding language in physical space, resolving ambiguity, and minimizing latency for real-time use.
W
Whole-Body Control
Whole-body control lets humanoid robots coordinate arms, legs, torso, and balance as a single system — solving for motion, torque, and task objectives across the entire body in real time. This enables complex actions like reaching while walking, shifting weight while lifting, or staying upright under external forces.
Today’s systems combine model-based controllers with learned policies for greater adaptability and fluidity. Frameworks like WBOSC, Drake’s QP solvers, Stack-of-Tasks, and TSID support whole-body planning in labs and commercial prototypes often layered into custom stacks like TWIST.
Wheeled
Wheeled robots are fast, efficient, and mechanically simple. They dominate warehouses, hospitals, and delivery fleets thanks to low energy use and easy control. Humanoid is currently developing its alpha-prototype for 2 platforms — wheeled and bipedal — starting with the wheeled one. It’s a safer, more controlled solution, which is also in higher demand: around 80% of use-cases in logistics can be automated using wheeled robots.
Some humanoid platforms experiment with hybrid designs adding wheels to feet or hips to combine walking and rolling. These systems offer speed on smooth terrain without sacrificing flexibility.
World Model
World models let humanoid robots plan by simulating. Instead of reacting only to real-time input, they forecast outcomes using internal representations of the environment — supporting long-horizon reasoning and closed-loop control.
Work on robot imagination and long-horizon planning explores how robots can simulate future scenarios and generalize across tasks using structured, multimodal representations, as seen in approaches like DreamerV3 and RoboDreamer.
As these systems mature, world models are becoming the foundation of embodied reasoning and adaptive control.
X
X-Axis Rotation
X-axis rotation, also known as pitch, describes how a robot pivots around its left–right axis. It enables nodding, leaning, bowing, or squatting motions, and plays a key role in posture adjustment and balance.
In humanoids, X-axis joints are typically found in the hips, knees, neck, and shoulders. At the system level, pitch control affects whole-body dynamics, fall recovery, and locomotion on uneven terrain.
Y
Y-Axis Rotation
Y-axis rotation, also known as yaw, describes how a robot pivots around its vertical axis to face left or right. It’s essential for reorienting the head, torso, or feet without taking a step.
In humanoids, Y-axis joints operate in the neck, waist, and ankles. This motion enables gaze shifts, mid-step adjustments, and full-body coordination during navigation. Precise yaw control lets robots track objects, align with tasks, and avoid obstacles without relying entirely on locomotion.
Z
Zero Moment Point (ZMP)
ZMP is the location on the ground where the combined tipping effects of gravity and inertia cancel out. As long as this point stays within a robot’s support area, the motion remains dynamically stable.
ZMP-based planning underpins model-driven walking control — stabilizing steps, shifting weight safely, and responding to disturbances in real time.

ZMP defines where a robot’s support forces cancel tipping. Keeping it within the foot area ensures stability during locomotion. Source: A Physically-Based Motion Retargeting Filter
While newer methods blend ZMP with learned dynamics, it remains a core tool for making humanoid motion stable and predictable.
Zero-Shot
Zero-shot capability in humanoid robotics refers to a system’s ability to perform a task it has never encountered during training without task-specific fine-tuning or demonstrations. This relies on generalization: mapping from high-level instructions or observations to effective actions based on prior knowledge.
Large foundation models, especially those integrating language and vision, are driving this capability. For example, a humanoid robot using a vision-language-action model might receive a prompt like “pick up the blue book on the shelf” and successfully complete the task despite never having seen that exact combination of object, color, or location before.
Zero-shot performance marks a shift away from rigid, pre-programmed routines toward open-ended generality.